I am not tech savvy.
Because I am an historian, this usually does not cause much surprise. Classes are often quite prepared to accept my “I am still a Luddite” approach to technology in the lecture hall while I fumble around with opening up a PowerPoint or curse YouTube for yet another completely ill-timed advertisement during whatever clip I’m trying to show. Those examples, of course, presume that I have already triumphed in getting the screen projector to work.
Zoom has been pretty interesting. (“Professor, you’re still on mute.” “Damnit!”)
As I told a class the other night, there are days when I truly I miss the old rétroprojecteurs with their flimsy transparents or when teachers would wheel in the big TV and VCR on a 5 ft. high trolley because something important needed to be seen by the entire class (I wasn’t alive in the 1970s, but still).
I know that I will never be the most technologically capable person in a given room. All of this is important background in understanding why our current regression-model-research-phase has felt rather daunting.
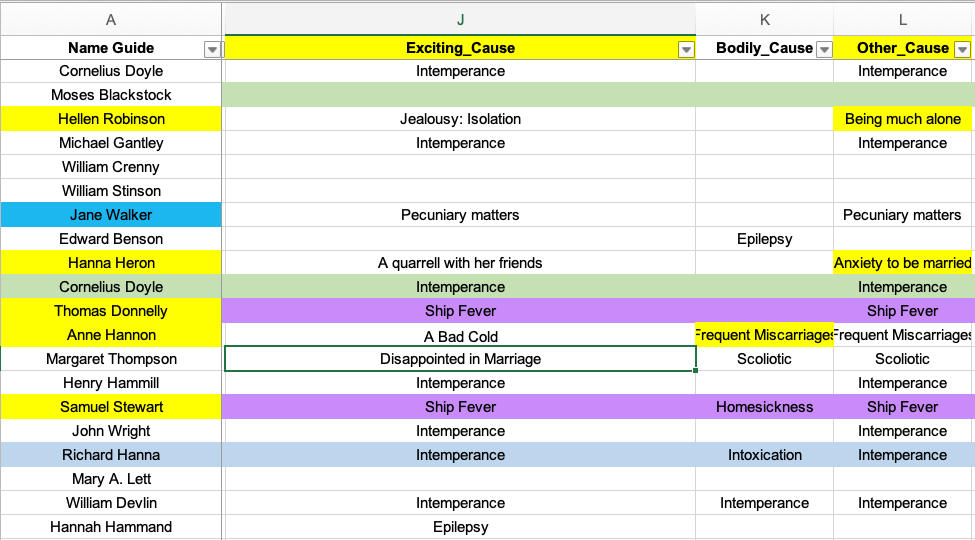
My confession: I don’t know how to use Excel.
Until this project started coming together, I had only ever used that software to file students’ names and calculate by hand their marks for each assignment in a term and then type the results into the little columns. Excel was the place where you put lists of things. It was a computerized notebook. I didn’t know it could do the math for you. Mea culpa.
I am still in awe when someone knows all the little codes and official functions that can make magic happen on the screen. I’m trying to master only half a dozen of those formulas and they are already giving me a feeling of immense power over our quantitative data that I never expected. There are things to do beyond basic percentages! And you don’t need to do any of the math yourself! It’s amazing!
That said, I have a lot of the same feelings that the research team has already expressed about the difference between our quantitative numbers and our qualitative sources – the primary documents giving us real voices from the past and a visceral sense of individual Irish women and men who, because of a wide variety of circumstances, ended up in the asylum system in the Canadas. In the end, the former will allow us to make qualifications that are not just based on emotional or discursive analysis, but also on verifiable figures and probabilities.
One goal we’re aiming for by introducing this new kind of methodology is to be able to present a much more rounded picture of specific individuals who made the journey from Ireland to Canada during the Famine years. We want to trace, step by step, what they went through from the time they left Ireland to their encounters with the medical and judicial systems in Canada East and Canada West (as you often needed to pass through the courts and jails in order to be admitted into the colony’s asylums). Those lived experiences come to life through specific medical files and case histories, government reports and correspondence, court documents, contemporary newspapers, and official census records. Now, with the new regression-based data, we can contextualize the probability that the presentation of a specific illness or type of behaviour by an Irish immigrant would result in asylum incarceration.
I just need to get over my fear of having a computer count the numbers instead of using my abacus.
~ JMcG

